Overview
This work evolved from an MSc research project at Imperial College London with the goal of developing
a foundational deep learning surrogate model for wildfire spread, based on the SCALED model developed by Yueyan Li.
Following the methodology of Burge et al. (2023),
data was generated using ELMFIRE.
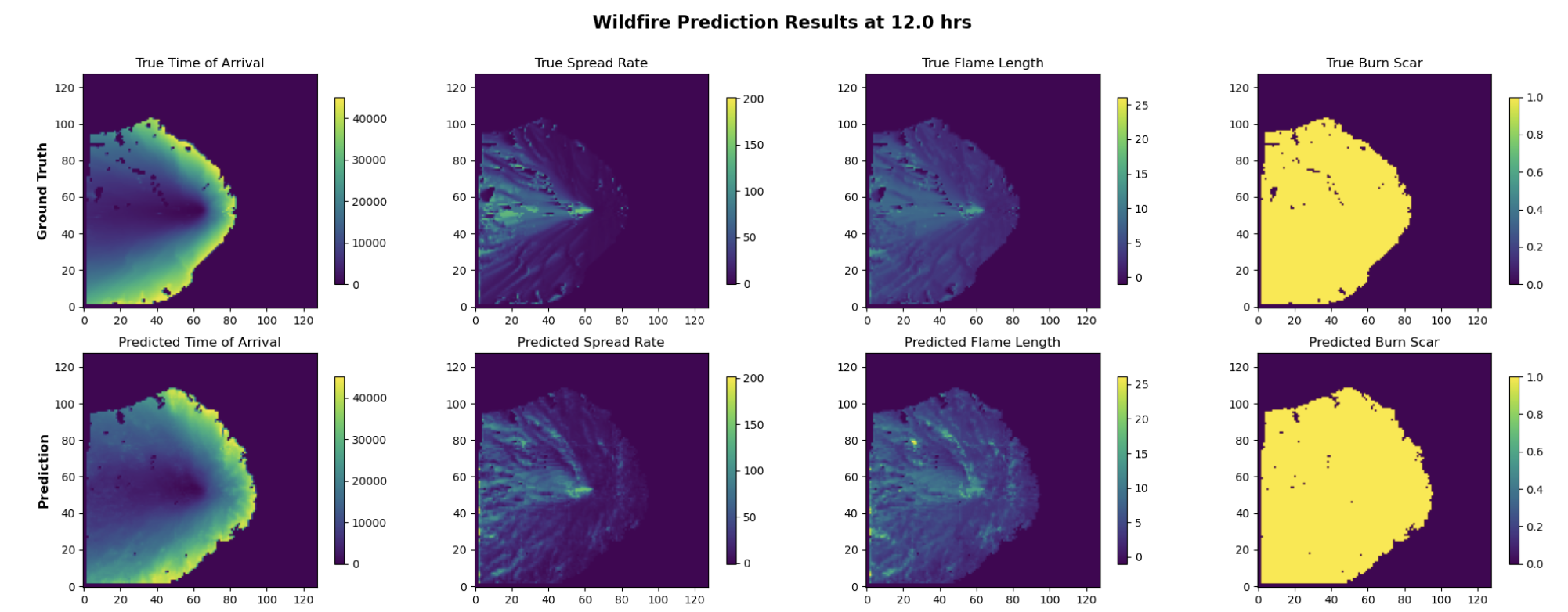
This visualization compares the model's prediction of the wildfire spread and the ground truth over 12 hours of autoregressive rollout,
at each step using the model's prediction as input for the next prediction. The first row shows the ground truth from ELMFIRE,
while the second row shows the model's prediction for time of arrival of the fire front, spread rate, flame length, and burn scar.
You can find the repository for this project at https://github.com/matheuboucher/WildfireModeling.